
Introducción
En este último post de la serie sobre el framework Ray vamos a profundizar en el uso de su librería RLlib (Reinforcement Learning Library) para entrenar algoritmos de aprendizaje por refuerzo en entornos simulados y reales y como utilizar toda la potencia de Ray para entrenarlos, tunearlos y servirlos.
Ray es un framework de Python que permite la ejecución de aplicaciones Python en paralelo y de forma distribuida. Está diseñado principalmente para ser usado en aplicaciones de Machine Learning y AI, pero también se puede usar en cualquier aplicación Python que requiera computación distribuida.
En el primer post de la serie Cluster Ray vimos como desplegar un cluster de Ray en una sola máquina con Dockers (Docker Compose) y explicamos por encima las distintas partes del framework: Ray Data, Ray Train, Ray Tune, Ray Serve y como se puede usar ésta última, Ray Serve, para servir un modelo de Hugging Face que traducía textos del inglés al francés.
Y en el siguiente Cluster Ray II desplegamos un cluster de Ray on premise en varias máquinas de producción y como entrenar y servir los modelos de machine learning que necesitan nuestros productos en él.
RRLib Aprendizaje por Refuerzo con Ray
El aprendizaje por refuerzo (RL) es un área del aprendizaje automático (ML) inspirada en el aprendizaje por ensayo y error utilizado por los humanos, donde un Agente aprende a tomar decisiones óptimas en un entorno para maximizar una recompensa acumulada. A diferencia del aprendizaje supervisado, donde se le proporciona al Agente un conjunto de datos de entrada y salida, en el RL, el Agente aprende por sí mismo a través de la interacción con el entorno.
Componentes clave del aprendizaje por refuerzo:
- Agente: La entidad que toma decisiones e interactúa con el entorno.
- Entorno: El mundo en el que opera el Agente, proporcionando al Agente información de estado y recompensas por sus acciones.
- Acciones: Las opciones disponibles para el Agente en cada estado.
- Estado: La representación de la información relevante del entorno para el Agente en un momento dado.
- Recompensa: La señal de retroalimentación que indica al Agente qué tan buena fue su acción.
- Función de valor: Estima la recompensa esperada a largo plazo a partir de un estado dado.
- Política: Define la probabilidad de que el Agente tome cada acción en cada estado.
Funcionamiento del entrenamiento de un algoritmo de aprendizaje por refuerzo:
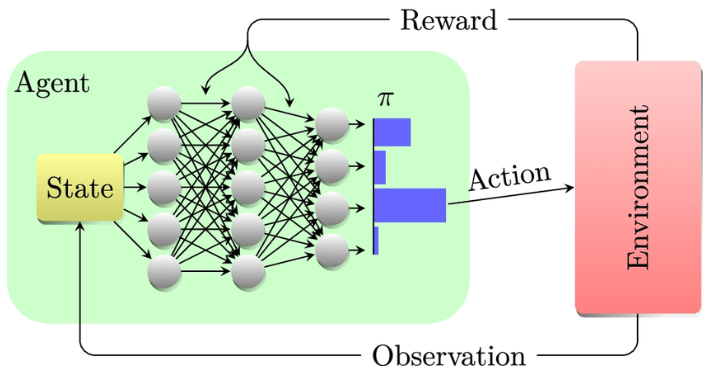
- 1.- El Agente observa el estado actual del entorno.
- 2.- Selecciona una acción según su política actual (que irá refinando en el entrenamiento).
- 3.- El entorno ejecuta la acción y proporciona al Agente un nuevo estado y una recompensa.
- 4.- El Agente actualiza su función de valor y su política en función de la recompensa recibida.
- 5.- Los pasos 1-4 se repiten hasta que el Agente alcanza un estado terminal o se cumple un criterio de parada.
Cuando termina el entrenamiento el Agente es capaz de “moverse” por el entorno y según el estado del mismo decidir que acción debe tomar para resolver el problema (maximizar la recompensa acumulada).
Ray RLlib es una biblioteca de aprendizaje por refuerzo escalable y distribuida que proporciona una implementación de alto nivel de algoritmos de aprendizaje por refuerzo.
RLlib se integra con Ray para proporcionar una API simple y escalable para entrenar y evaluar modelos de aprendizaje por refuerzo. RLlib incluye implementaciones de algoritmos de aprendizaje por refuerzo de vanguardia y herramientas para evaluar y analizar los resultados de los entrenamientos de esos aprendizajes.
Ejemplos de uso de RLlib
Frozen Lake
El problema Frozen Lake es un entorno clásico de aprendizaje por refuerzo (RL). Este entorno simula un escenario en el que un Agente debe navegar por un lago helado para llegar a un objetivo. El lago está formado por casillas, algunas de las cuales son seguras y otras son agujeros de hielo. El Agente puede moverse en las cuatro direcciones cardinales (arriba, abajo, izquierda y derecha). Si el Agente se mueve a una casilla con un agujero de hielo, cae en él y recibe una recompensa negativa. El objetivo del Agente es llegar a la casilla objetivo en el menor número de pasos posible, evitando caer en los agujeros de hielo.
En los algoritmos de aprendizaje por refuerzo de RRlib se puede usar entornos definidos con la biblioteca Gymnasium de OpenAI.
En Gymnasium se pueden encontrar muchos entornos de aprendizaje por refuerzo predefinidos, como el Frozen Lake, que se pueden usar para entrenar Agentes de aprendizaje por refuerzo.
Vamos a redefinir el entorno Frozen Lake de Gymnasium para entender los conceptos del aprendizaje por refuerzo y entrenar un Agente con RRlib.
|
|
Podemos “movernos” dentro del entorno con el siguiente código:
|
|

Los conceptos clave en el Aprendizaje por Refuerzo en este entorno son:
- Estados: El estado del entorno es todo lo que describe el entorno: El tablero, dónde están los hoyos y la casilla en la que se encuentra el jugador.
- Acciones: Las acciones disponibles para el jugador son moverse en una de las cuatro direcciones cardinales (izquierda, abajo, derecha, arriba). Cada acción se representa como un número entero de 0 a 3.
- Observaciones: La observación es la parte del entorno que el Agente puede ver. En este caso es un número entero que va de 0 a 15 que indica en qué casilla está el jugador. En este caso el Agente solo puede ver la casilla en la que se encuentra y no le dejamos ver dónde están los hoyos para que lo tenga que aprender con ensayo y error como evitarlos. Si complicamos el entorno y los agujeros son aleatorios, ayudaráimos al Agente por ejemplo añadiendo en las observaciones los hoyos cercanos que tiene a su alrededor.
- Recompensas: El jugador recibe una recompensa de 1 si llega al objetivo y 0 en caso contrario.
- Terminación: Llamamos episodio al conjunto de acciones que terminan si el jugador llega al objetivo o cae en un agujero de hielo.
Y las funciones que se pueden usar en este entorno son:
- reset: Inicializa el entorno y devuelve el estado inicial.
- observation: Devuelve la observación actual del entorno. En este caso, la casilla en la que se encuentra el jugador.
- reward: Devuelve la recompensa actual del entorno. En este caso, 1 si el jugador llega al objetivo y 0 en caso contrario.
- done: Devuelve True si el episodio ha terminado y False en caso contrario.
- step: Realiza una acción en el entorno y devuelve la observación, la recompensa, si el episodio ha terminado y la información adicional.
- render: Imprime el estado actual del entorno en la consola.
Ahora podríamos entrenar un algortimo de RRlib pasándole el entorno que hemos definido para que en su entrenamiento utilice estas funciones siguiendo los siguientes pasos por cada episodio de entrenamiento:
Mientras el episodio no haya terminado (done):
- 1.- Inicializar el entorno (reset)
- 2.- El Agente observa el estado actual del entorno (observation)
- 3.- El Agente selecciona una acción según su política actual
- 4.- El entorno ejecuta la acción (step) y proporciona al Agente un nuevo estado y una recompensa
- 5.- El Agente actualiza su función de valor y su política en función de la recompensa recibida (reward)
El código de entrenamiento sería :
|
|
Estamos entrenando un algoritmo PPO (Proximal Policy Optimization) en el entorno Frozen Lake que hemos definido. El entrenamiento se realiza en 10 iteraciones y se imprime el resultado de cada iteración. Cada 5 iteraciones se guarda un checkpoint del modelo entrenado.
PPO es un algoritmo clasificado como on-policy, lo que significa que implementan una política que decide qué acción tomar en cada momento de forma explícita y off-model que significa que no necesita un modelo predefinido de transición de estado para entrenar. El modelo de política del PPO se basa en redes neuronales artificiales y entra dentro de la categoría de algoritmos de políticas de gradiente.
PPO es un algoritmo de aprendizaje por refuerzo de vanguardia que ha demostrado ser eficaz en una amplia variedad de entornos de aprendizaje por refuerzo, pero podemos entrenar otros muchos algoritmos de aprendizaje por refuerzo de RRlib como DQN, A3C, etc.
Para utilizar el modelo entrenado y resolver el problema de alcanzar la casilla de salida, usaríamos el siguiente código:
|
|
Alarmas en una Central eléctrica
Tenemos una central electrica con un histórico de datos de varios años de alarmas que se han producido en ella cuando surgen problemas en su suministro. Queremos entrenar un Agente que sea capaz de predecir si se va a producir una alarma con una antelación de 15 minutos y así poder tomar medidas preventivas.
Para ello vamos a definir un entorno de aprendizaje por refuerzo que simula el entorno de la central eléctrica con los datos del suministro de electricidad.
|
|
Cómo podemos ver en los comentarios del código anterior, los conceptos clave en el Aprendizaje por Refuerzo en este entorno son:
- Estados: El estado del entorno es todo lo que describe el entorno. El histórico de datos de la central eléctrica y las alarmas que se han producido en ella.
- Acciones: Las acciones disponibles para el Agente son predecir si se va a producir una alarma en los próximos 15 minutos o no. Cada acción se representa como un número entero de 0: NO SE VA A PRODUCIR o 1: SI SE VA A PRODUCIR.
- Observaciones: La observación es la parte del entorno que el Agente puede ver. En este caso es un conjunto de arrays de 4 números que indica las características de la central (frecuencia, carga, potencia, desviación de frecuencia) en cada uno de últimos 15 minutos.
- Recompensas: El Agente recibe una recompensa de +10 si predice que se va a producir una alarma en los próximos 15 minutos y acierta, de -10 si predice que se va aproducir una alarma pero no acierta y de -10 si predice que no se va a producir y al final si se produce.
- Terminación: Un episodio termina si el Agente ha recorrido todo el histórico de datos de la central eléctrica.
Y las funciones que se pueden usar en este entorno son:
- reset: Inicializa el entorno y devuelve el estado inicial. En este caso, el estado inicial es la información histórica de los primeros 15 minutos.
- observation: Devuelve la observación actual del entorno. En este caso es la información histórica de los últimos 15 minutos.
- reward: Devuelve la recompensa actual del entorno.
- done: Devuelve True si el episodio ha recorrido todos los datos históricos.
- step: Realiza una acción (Predecir si va a haber una Alarma o no) y devuelve la observación, la recompensa, si el episodio ha terminado y la información adicional.
- render: Imprime el estado actual del entorno en la consola.
Para entrenar y usar el modelo entrenado en este entorno, se seguirían los mismos pasos que en el entorno Frozen Lake.
Ray Framework
Jobs:
Si ponemos el código del entrenamiento en un fichero llamado train.py, podemos lanzar el entrenamiento dentro del cluster de Ray con el siguiente comando:
|
|
Hyperparameters Tuning:
Si queremos hacer un ajuste de hiperparámetros, podemos usar la biblioteca Tune de Ray. Tune es una biblioteca de ajuste de hiperparámetros escalable y distribuida que proporciona una API simple para ajustar hiperparámetros y realizar experimentos de aprendizaje automático.
En el caso de los ejemplos anteriores, podríamos ajustar los hiperparámetros de los algoritmos de aprendizaje por refuerzo de RRlib para mejorar su rendimiento.
Estos algoritmos pueden tener hasta 129 hiperparámetros que se pueden ajustar para mejorarlo. Algunos de los hiperparámetros más importantes son:
- lr: tasa de aprendizaje
- train_batch_size: número de iteraciones de datos que se agruparán juntos
- sgd_minibatch_size: tamaño del minibatch para SGD (descenso por gradiente estocástico)
- num_sgd_iter: épocas de SGD por iteración de PPO
- entropy_coeff: mide la cantidad de exploración durante el entrenamiento
- model architecture: Arquitectura de la red artificial de las políticas (acciones a llevar a cabo)
Por ejempo si queremos ajustar el hiperparámetro lr (learning rate) del algoritmo PPO de RRlib, podríamos hacerlo con el siguiente código:
|
|
También se pueden ajustar multiples parámetros a la vez con Tune usando una búsqueda “Grid Search” que prueba todas las combinaciones posibles de los hiperparámetros que le especifiquemos.
Ray Serve
Ray Serve es un framework de Python que permite la creación de servicios API REST escalables y de alto rendimiento. Ray Serve se integra con Ray para proporcionar una API simple y escalable para servir modelos de aprendizaje automático y aplicaciones web.
Podemos usar Ray Serve para servir modelos de aprendizaje por refuerzo entrenados con RRlib y hacer predicciones en tiempo real.
Ray Distributed Training
También podemos aprovechar toda la potencia de Ray para entrenar modelos de aprendizaje por refuerzo en paralelo y de forma distribuida. Ray proporciona una API simple y escalable para entrenar y evaluar modelos de aprendizaje por refuerzo en clústeres de máquinas.
|
|
Expecificando num_rollout_workers=4, estamos diciendo a RRlib que use 4 workers para recoger datos del entorno en paralelo. Para la mayoría de los entornos de simulación se puede replicar el entorno en un clúster. Por lo tanto, se pueden recoger datos mucho más rápido y evitar el cuello de botella del entrenamiento. Sea cual sea el clúster al que Ray esté conectado en el backend, num_rollout_workers=4 funciona sin problemas.
Redes Neuronales Artificiales
Muchos de los modelos de aprendizaje por refuerzo de RRlib (PPO, DQN, etc) utilizan redes neuronales artificiales para aproximar la función de valor y la política.
En RRLib podemos definir la arquitectura de las redes neuronal de la política y de la función de valor creando un Modelo a medida tanto en TensorFlow como en PyTorch.
Conclusión
En este post hemos visto como usar RRlib para entrenar algoritmos de aprendizaje por refuerzo en entornos simulados y reales y como usar la potencia de la plataforma distribuida de Ray para entrenarlos, tunearlos y servirlos.
Y por fin (ya era hora) hemos terminado la serie de posts sobre Ray
Referencias
- 1.- Ray
- 2.- RRlib
- 3.- Gymnasium
- 4.- Tune
- 5.- Ray Serve
- 6.- Ray Distributed Training
- 7.- Curso seguido en este POST

